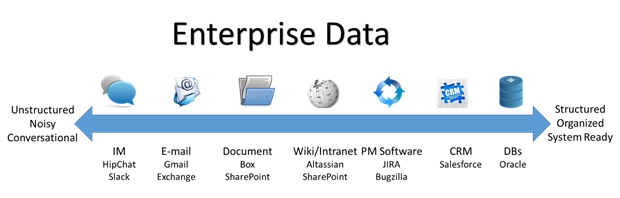
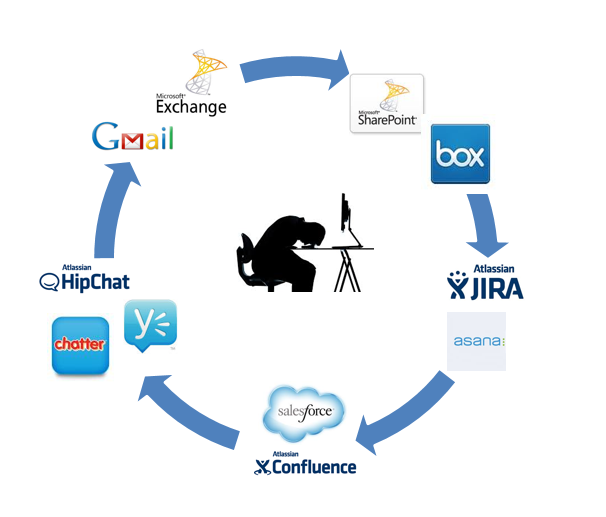
Imagine, for a moment, that you are involved with an important update. Maybe you were an engineer or coder on the project, or perhaps you were a product manager charged with seeing the update through. Consider:
- How do you announce the update to the rest of your organization?
- How do you field the dozens (maybe even hundreds) of potential questions, once that announcement is made?
- Most importantly, how do you make that information “top of mind” when the sales team is out in the field?
In a previous post, we discussed the disconnect that often occurs between sales teams, on the one hand, and subject matter experts (SMEs), on the other. In that article, our focus was on how this disconnect affects sales productivity. Sales reps often rely on sales enablement and product/technical marketing to provide them with technical information about product features, capabilities, solutions, and roadmaps; searching for that information can eat away at reps’ valuable time.
It is also worth exploring how various SMEs—including product experts, engineers, project managers, and even marketing specialists—are affected by this gap. As it turns out, SMEs are often hindered by outdated methods of knowledge management. It’s time for modern enterprises to fix that.
Every Subject Matter Expert Deals with These Hassles
Speaking with SMEs from a number of industries, one finds some common threads in the kinds of problems they identify as hindrances to their productivity. Here are the top four we discovered:
#1: Repetitive Requests for Information
Based on conversations with SMEs, we estimate that more than a third of the requests for information that SMEs receive on a daily basis are requests for redundant information—that is, information the SME has already made available. This could be because:
- Multiple sales reps all ask the same question separately,
- The information is readily available in an electronic document or wiki, but the rep did not have access or know about the resource,
- A question was answered in a previous conversation, but there was no easy way to uncover the answer, or
- Any combination of these.
Huge amounts of SME time are occupied with responding to questions that have already been asked and answered, and providing documentation that is readily available. Knowledge management tools might help organize and centralize this information, but distribution is still a problem. Sales and customer service reps need this information at their fingertips, in real time—a luxury that produces an undue burden on SMEs.
#2: Documentation Woes
SMEs are often called upon to create content that is, in turn, consumed by many others in the organization. In many large and enterprise-sized organizations, those SMEs will use wikis and other content management systems to make information available. Uptake and use of these systems varies by company and is largely affected by the company culture, amount of training on the system, and comfort with the technology.
Indeed, many sales and service reps are unaccustomed to using the tools that are the bread-and-butter for SMEs. This means that they often cannot (or will not) get the most up-to-date information.
This has a subtle but large impact on the effectiveness of sales messaging. Indeed, 55% of organizations claim that they fail to communicate their value effectively because reps fail to find and utilize tailored content. In essence, all the documentation that SMEs are creating becomes wasted effort if not used in a timely manner.
#3: Lack of Quality Checks on Content
Even when SMEs create content and make it available, sales teams will still create their own. For example, an engineer might develop dozens of technical documents and sales sheets, but the sales team will still create their own PowerPoint deck.
The problem with traditional knowledge management systems is that there is no good mechanism to check the accuracy and quality of that non-SME-generated content. Information tends to flow from the experts to the frontline employees, but there is no system in place to flag content for expert review and facilitate feedback.
This creates a huge amount of frustration for SMEs. It also causes problems for sales teams, who must often “walk back” promises made or qualify information they have given customers, all of which negatively affects the brand.
#4: Frequent Training Might Not Be an Option
One common solution to the above for many organizations is training. Companies will attempt to bring their frontline employees, as well as their SMEs, up-to-date on the latest product and market information.
This is becoming less and less of an option. Larger organizations could well be dealing with thousands of products, all of which have frequent updates and expert-generated content. Sitting everyone down in a room for an afternoon soon becomes unscalable. Providing training for older content management systems only exacerbates the problem.
#5: Much Information is “Long Tail”
The information needed to address a customer’s question or complaint can often be highly specific, and not general at all. In content circles, this is known as “long tail” information. With traditional knowledge management, that information might be buried deep down in some faq or spec sheet. The more bits of such “long tail” information there are, the worse the problem becomes. SMEs often end up spending huge amounts of time trying to organize this long tail information, and yet those across the organization who need it still cannot find the specific bits they need.
Getting SMEs Productive Again
We’ve found that the above complaints have a common, core cause. SMEs are generating large amounts of information, both formally and informally, that are highly “consumed” across the organization. But, as much of this information includes smaller pieces of highly specific (long tail) knowledge, it is virtually impossible to structure and manage this information without creating huge burdens for someone.
This means that one must be willing to abandon the older model of disseminating information within an enterprise organization. Modern technology can then be used to automatically build the needed structures on the fly.
For example:
- Product updates can be handled in real time without the need for a centrally managed database.
- APIs allow for seamless integration of existing systems such as CRM, sales enablement, customer service, and more.
- Data-driven (vs. algorithm-driven) search tools allow for real-time search of unstructured data, including not only wikis and databases, but email conversations, chat channels, and more.
- Better user interfaces put relevant answers to questions right at an employee’s fingertips, at the moment they are needed.
Solutions that bundle these technologies, like our own Nimeyo, often go under the label of knowledge automation. Knowledge automation makes the dissemination of information faster and more seamless, allowing SMEs to focus on their primary tasks and without the need for extensive training. Nimeyo, for example, automatically builds structures from SMEs contributions and dynamically disperses them to the right individuals, addressing the above complaints in an elegant and scalable manner.
And in the end, is this not the goal? To keep information accessible, useful, and relevant without overburdening those tasked with creating it in the first place?